
티스토리 뷰
Architectural patterns & best practices #3 Data Storage
에디.이이 2021. 7. 12. 22:19AWS의 Solutions Architect인 Arthi Raju가 AWS re:Invent 2020 온라인 행사에서 발표한
'Architectural patterns & best practices for workloads on VMware Cloud on AWS'에 대해 정리해 봅니다.
---------------------------------------------------
1편. AWS Network Architecture
2편. VMware Transit Connect
3편. Data Storage (이번글)
---------------------------------------------------
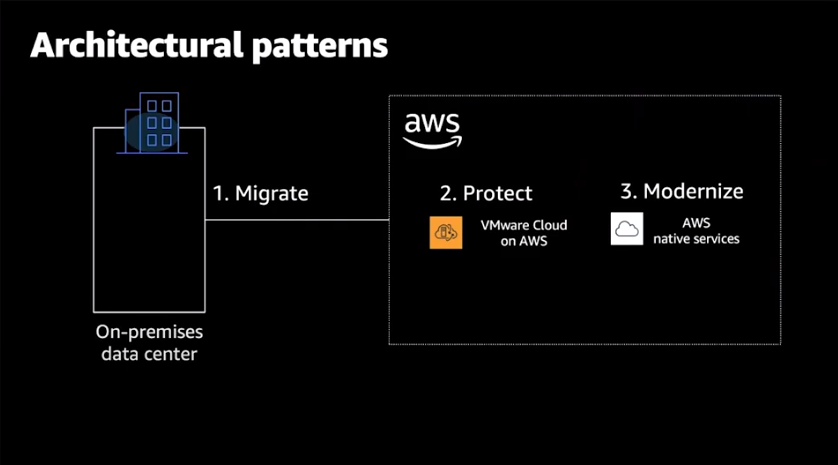
On-premise에서 실행되는 워크로드를와 AWS인프라로 이전하거나,
On-premise와 AWS에서 하이브리드 형태로 워크로드가 구현될 때 스토리지에 대해 고민해보겠습니다.
데이터 스토리지 측면에서는 클라우드로의 전환을 시작하기 위해 고민해야 할 세 가지 중요한 주제가 있습니다.
첫 번째 중요한 주제는 가상머신의 마이그레이션입니다.
데이터가 AWS의 인프라로 마이그레이션되고 나면,
사용자들은 높은수준의 가용성, 성능, 확장성, 비용최적화 및 복원력을 보장 및 데이터 보호전략을 필요로 합니다.
따라서, 사용자의 클라우드 활용 사례에 따라 데이터 접근 방식의 개선이 필요합니다.
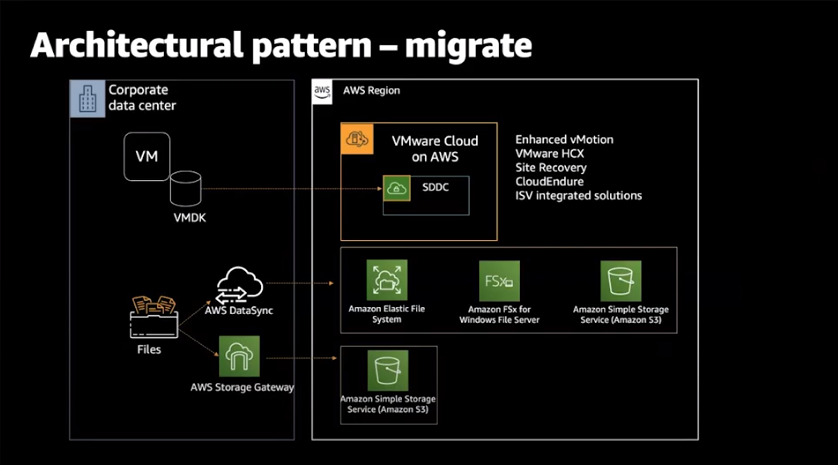
VMware vSphere에서는 가상머신의 디스크 파일, 즉 VMDK를 가지고 있습니다.
가상머신은 하나 이상의 VMDK를 가질수 있으며, VMDK는 가상머신에서 애플리케이션을 위한 저장공간을 제공합니다.
사용자는 각 가상머신들이 On-premise에서 SDDC로 전환될 때 순조로운 마이그레이션이 되기를 원하며,
AWS는 가상머신의 VMDK에 어떠한 인의적 변경을 통해서 Amazon AMI(Amazon Machine Images)로 전환을 하거나,
EBS 볼륨의 추가적인 구성을 통한 마이그레이션이 진행되기를 원하지 않습니다.
따라서, On-premise와 AWS의 동일한 하이퍼바이저 환경을 통해 가상머신에게 동일한 운영환경을 제공하며,
별도의 다운타임 없이 워크로드를 이동하기 위한 다양한 방법과 도구를 제공하고 있습니다.
첫번째, Direct Connect 환경에서 동작할 수 있는 vMotion을 지원하고 있습니다.
두번째, 수백/수천대의 가상머신을 대량으로 마이그레이션 할 수있는 HCX(Hybrid Cloud eXtension)를 제공합니다.
HCX는 다수의 마이그레이션하고자 하는 가상머신을 선택하고, 시작 시기와 시스템 전환 시점을 선택할 수 있음으로,
별도의 시스템 이미지의 변환이나 사용자 관리 내역를 변경하지 않고도 손쉽게 마이그레이션 가능합니다.
세번째, VMware 사용자에게 익숙한 Site Recovery가 있습니다.
SRM은 On-premise에서 클라우도로의 DR 보호를 제공하거나, 워크로드의 마이그레이션 기능을 제공합니다.
사용법은 마이그레이션하고자하는 가상머신의 그룹을 정의하고, 데이터 보호를 적용만 하면 바로 구성됩니다.
네번재, On-premise에서 native AWS로 마이그레이션을 지원하는 CloudEndure가 있습니다.
마지막, 백업 및 데이터 보호를 위한 3rd party 솔루션을 활용할 수 있습니다.
이미 Veeam이나 Commvault, Veritas, IBM Spectrum과 같은 다양한 데이터 보호 솔루션들이
VMware Cloud on AWS에서 사용할 수 있도록 인증되어 있으며, 정상적인 동작이 검증되었습니다.
또한, 사용자들은 애플리케이션의 요구에 따라 다양한 비정형데이터나
다른 서비스 목적의 데이터들을 On-premise에 보유하고 있으며, 이 데이터도 AWS로 백업하기를 바랍니다.
이를 위해 AWS에서는 사용자 데이터의 쉬운 이전을 위한 다양한 솔루션과 방법들도 제공합니다.
첫번째, AWS의 DataSync가 있습니다.
Datasync는 AWS에서 다운받은 가상머신을 On-premise의 vCenter 환경에 설치하여 사용합니다.
설치된 가상머신을 통해 데이터를 NFS 서비스를 위한 Elastic File System이나,
Windows 가상머신에게 SMB 서비스를 제공하는 FSX 서비스로 이전합니다.
또한, 데이터 보호 및 분석 요구사항을 위해 높은 내구성 및 가용성을 가진 Amazon S3로 이전할 수도 있습니다.
두번째, AWS Storage Gateway를 제공합니다.
Storage Gateway는 일반적으로 볼륨 기반의 파일 게이트웨이나 VTL과 함께 데이터보호의 목적으로 사용됩니다.
이 역시 On-premise에 가상머신 형태로 설치되어, Amazon S3와 연동되며,
On-premise의 가상머신들에게 NFS나 SMB 형태로 파일 공유를 제공합니다.
이를 통해 데이터가 다양한 AWS 서비스로 마이그레이션 될 수 있도록 도와줍니다.

두번째 중요한 주제는 데이터의 보호입니다.
VMDK 기반의 스토리지에는 3가지 주요 설계 원칙이 반영되어야 합니다.
첫번째, vSAN의 스토리지 정책입니다.
vSAN은 vSphere 하이퍼바이저에서 실행되는 가상머신들에게 VMDK 기반의 스토리지를 제공하는
VMware의 소프트웨어 정의 스토리지(Software-Defined Storage) 솔루션입니다.
vSAN의 스토리지 정책은 워크로드가 SDDC로 마이그레이션될 때 적용됨으로,
사전에 클러스터 또는 데이터스토어의 최대 허용 장애 호스트 수에 대한 정책을 정의해야 합니다.
최대 허용 장애 호스트수는 하나 또는 두개의 장애를 허용할 수 있으며,
기본적으로는 하나의 호스트 장애이나, 호스트가 6대 이상일 경우 FTT는 두대로 구성하는 것을 권장합니다.
FTT=2는 RAID6이며, 스토리지 정책의 RAID 6의 사용은 성능과 가용성간의 균형을 위한 권장사항입니다.
일반적인 native AWS에서는 가용성을 위해 고객의 워크로드를 여러개의 AZ에 걸쳐 구축할 것을 권장하고 있으며,
VMware cloud on AWS에서도 같은 이유로 2개의 AZ에 걸쳐 SDDC를 구축하는 Stretched Cluster를 권장합니다.
두번째, 전체 스토리지의 여유 공간은 SDDC 클러스터내에서 25%를 유지하기를 권장합니다.
만약 SDDC의 여유공간이 25%보다 아래로 줄어들게 되면,
Elastic DRS(Distributed Resourc eSchdeular)에 의해 자동으로 용량이 추가되도록 설계되어 있습니다.
세번째, 또하나 명심해야 할 가장 중요한 것은 정기적인 백업입니다.
기본적으로 고성능 NVMe 스토리지는 가상머신을 위한 데이터저장소 역할에 충실하며,
백업은 SDDC의 저장공간과 별도로 분리된 서비스형 저장공간에 저장하는 것을 권장합니다.
즉, 백업의 저장을 SDDC 내부가 아닌 native AWS의 스토리지 서비스를 이용하여 저장합니다.
백업을 위해 각각의 ESXi 호스트에 연결되어 있는 ENI 네트워크를 이용할 수 있으며,
백업 솔루션이나 가상머신이 S3나 FSX, EFS의 native AWS의 스토리지 서비스에 원할하게 접근할 수 있습니다.
native AWS의 스토리지는 모두 서비스형으로 제공되기 때문에,
사용자는 별도의 모니터링 솔루션이나 고가용성등에 대해 걱정할 필요없이 즉시 사용이 가능합니다.

데이터는 기본 서비스 보호 정책에 따라 관리되며 사용자는 고가용성 등 관리에 대해 신경쓸 필요가 없습니다.
예를 들어, FSX의 경우 윈도우 서버의 VSS(Volume Shadow copy Service) 기능을 통합하여,
사용자가 특정 백업 스냅샷을 셀프 서비스 방식으로 복원할 수 있도록 하였습니다.
이제 아키텍트는 매일 반복되는 일상 작업에 대해 관여할 필요가 없습니다.
또한, 사용자는 백업 정책의 구성을 통해서 데이터 보호가 자동으로 이루어지도록 구성할 수 있습니다.
FSX 뿐만 아니라 EFS에서도 동일합니다.
만일 EFS에 자주 접근하지 않는 파일들이 장기간동안 공유되고 있다면,
DataSync를 통해 EFS Infrequent access로 이동하여 기존 스토리지 비용의 92% 이상을 절감할 수 있습니다.
마지막으로, Amazon S3는 Standard, Intelligent-Tiering(Infrequent Access), Glacier, Glacier Deep Archive 등의
다양한 스토리지 옵션을 제공하며, 사용자가 정의한 라이프 사이클 정책에 따라 구성됩니다.

세번째 중요한 주제는 데이터의 현대화(Modernaztion) 입니다.
Amazon S3와 같은 AWS 스토리지 서비스를 통해 데이터 아키텍처를 현대화할 수 있는 강력한 기반을 마련했습니다.
한 단계 더 나아가 데이터 파이프라인을 위한 ETL 작업을 통해 데이터의 중앙 집중식 카탈로그를 구축하면,
기본적인 데이터레이크 아키텍처로 전환되어 팀에 속한 데이터를 모아 새로운 Insight를 얻을 수 있습니다.
추가로, 누가 내 데이터 혹은 중앙 집중식 데이터 카탈로그에 접근할 수 있는지에 대한 보안 정책의 구성이 필요합니다.
만약 AWS Glue같은 서비스를 이용한면 데이터가 보관중이거나 전달될때 암호화 같은 기능을 통해 보안을 유지합니다.
이러한 보안 정책을 기반으로 규정 준수에 대한 요구 사항도 해결할 수 있습니다.
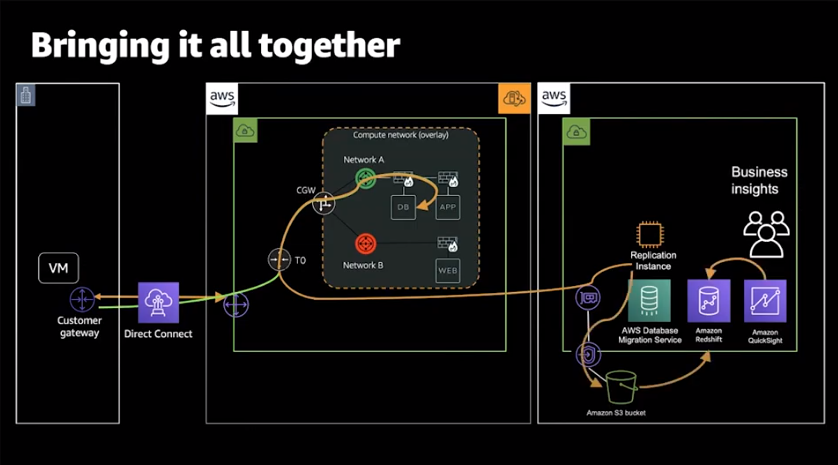
이를 지금까지의 내용을 종합한 실전 사례를 살펴보겠습니다.
On-premise의 데이터센터가 Direct Connect를 통해 VMware Cloud on AWS와 native AWS 서비스와 연결됩니다.
먼저, 기존의 On-premise에서 구동중인 데이터 기반의 워크로드는 SDDC로 아주 손쉽게 마이그레이션을 수행합니다.
이후 사용자가 가지고 있는 AWS 계정에 'Database Migration Service'를 배포합니다.
이제 SDDC에서 구동중인 Source Database를 지정하여 Amazon S3로 데이터를 가져옵니다.
가져온 데이터를 Amazon Redshift 클러스터를 적재하고, 비지니스 Insight를 가질수 있도록 도와줍니다.
기본적으로 Amazon Redshift는 Amazon QuickSight나 Tableau 등 다른 비즈니스 인텔리전스 도구를 사용하여
페타바이트 규모의 반정형 데이터 및 정형 데이터에 대해 간단하고 비용효율적인 고성능 쿼리를 실행합니다.
'에디.VMware > VMware Cloud on AWS' 카테고리의 다른 글
| i3.metal 기반 2 hosts 클러스터는 35대 VM까지 ON할 수 있습니다. (0) | 2021.09.30 |
|---|---|
| SDDC 버전별 세부 구성 요소 버전 (0) | 2021.07.21 |
| i3.metal 구성정보 (0) | 2021.07.08 |
| Architectural patterns & best practices #2 VMware Transit Connect (0) | 2021.07.01 |
| HCX 마이그레이션의 종류 (0) | 2021.06.29 |